While Text-to-Speech and Text-to-Audio generation have each achieved remarkable progress, existing dubbing systems remain confined to isolated speech synthesis without incorporating sound effects and ambient audio. We present HoliDubber, the first holistic video dubbing framework that moves beyond speech-only generation by enabling the joint synthesis of speech and sound effects from a single text prompt. HoliDubber adopts a patch-based autoregressive diffusion transformer architecture, where a causal language model autoregressively models aggregated patch embeddings for global temporal structure, and a Diffusion Transformer decoder generates high-fidelity continuous tokens within each patch. Visual features are fused with audio patches via cross-attention to ground speech generation in the speaker's visual articulation dynamics. We further introduce HoliDub-Bench, a benchmark with synchronized video-text-audio triplets for holistic dubbing evaluation. Extensive experiments demonstrate that HoliDubber significantly outperforms existing methods in speech quality, synchronization, and speaker similarity, establishing a new paradigm for holistic video dubbing in complex acoustic scenes.
Capabilities
Two Inference Modes
HoliDubber supports flexible dubbing via two complementary modes, enabled by a single unified model with stochastic text-field dropout during training.
🎙️
Zero-shot Dubbing
Given a reference speech clip, HoliDubber generates synchronized dubbing that preserves the vocal timbre and identity of the reference speaker — with no fine-tuning required.
✍️
Text-Prompt Guided Dubbing
Using structured text descriptions (speaker profile, speech instruction, audio caption), HoliDubber synthesizes both speech and sound effects without any reference audio.
Highlights
Key Contributions
01
Holistic Dubbing Framework
The first system to unify speech and sound effect generation within a single text-guided generative process, moving beyond speech-only dubbing.
02
Patch-based Audio-Visual Fusion
Cross-attention mechanism that fuses patch-level visual features with audio representations for fine-grained lip synchronization.
03
Multi-stage Training Pipeline
From large-scale TTA pre-training to structured-prompt fine-tuning with random field dropout, enabling flexible zero-shot and text-guided modes.
04
HoliDub-Bench
A curated benchmark of 1,000 clips with fine-grained acoustic annotations for evaluating holistic dubbing under complex acoustic environments.
Approach
Model Architecture
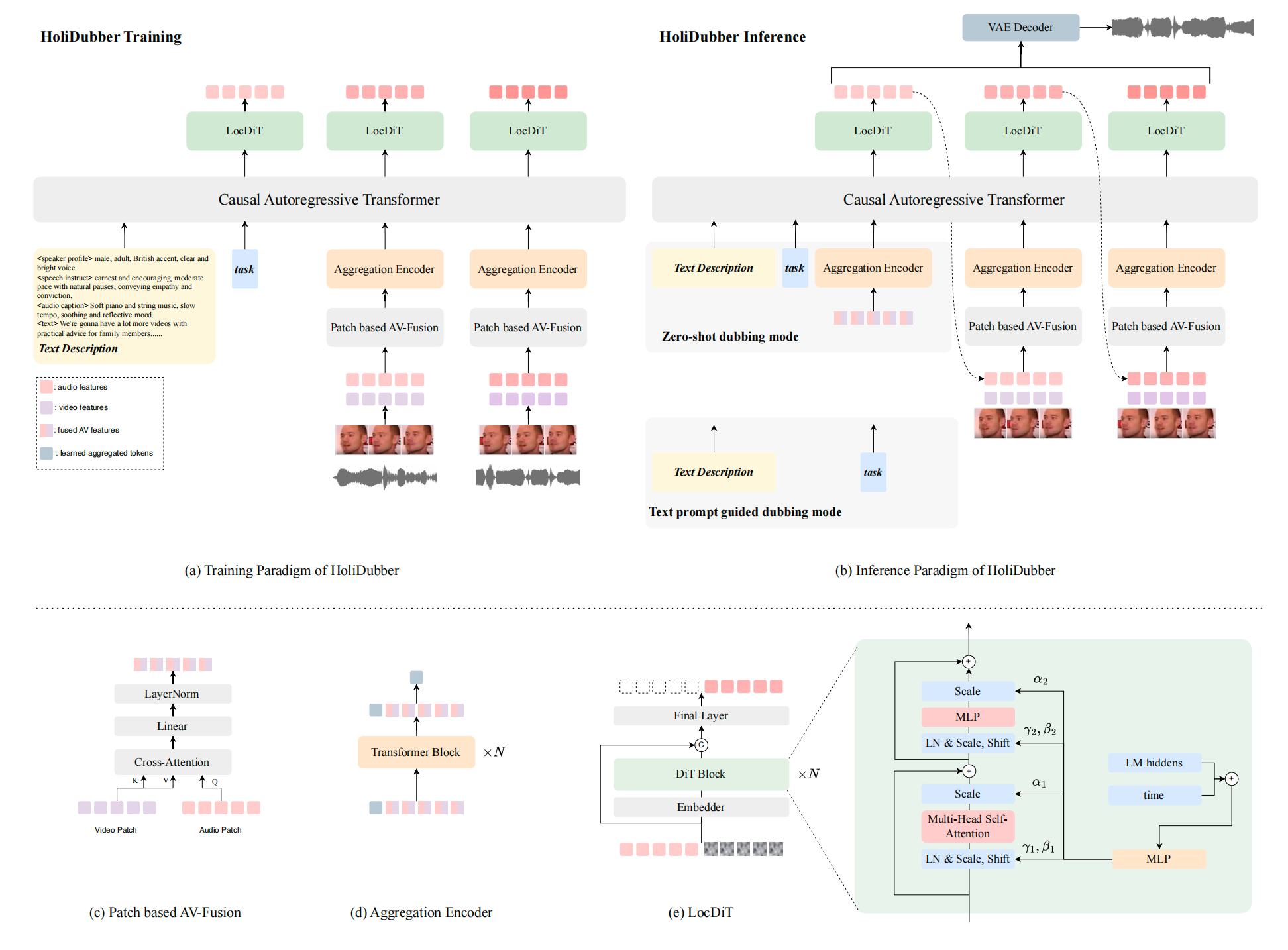
Figure 1. Overall framework of HoliDubber. (a) Training paradigm. (b) Inference paradigm supporting both zero-shot and text-prompt-guided modes. (c–e) Architecture details of patch-based AV-fusion, aggregation encoder, and LocDiT.
Step 1
Audio Captioning
Generate structured multi-field descriptions via Qwen3-Omni for speaker profile, speech instruction, and audio captions.
Step 2
AV Fusion
Patch-level cross-attention fuses video features with audio latents, attending to upcoming articulation for temporal alignment.
Step 3
Aggregation
Bidirectional transformer compresses fused multi-modal tokens into holistic patch embeddings via a learnable aggregation token.
Step 4
AR + LocDiT
Causal LM captures inter-patch structure; LocDiT synthesizes high-fidelity continuous audio tokens within each patch via flow matching.
Audio-Visual Demos
Dubbing Samples
Each video below contains the synthesized audio. Please unmute and play to compare lip synchronization, speech quality, and acoustic scene fidelity across different methods.
Zero-shotCelebvDub — Sample #1
<text>
They're really kind of opposite in their styles and his tone is so so unique.
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Zero-shotCelebvDub — Sample #2
<text>
And while it is easy to chalk up Shaggy's appetite to him being a stoner, ha ha, there was actually a canon alibi.
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Zero-shotCelebvDub — Sample #3
<text>
And that's great for a new business because more gigs, more work, more students equals more impact, more opportunity, and of course, more money.
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Zero-shotCelebvDub — Sample #4
<text>
If you saw my video about the custom Christian Clins with the salmon dial, you might remember that we spoke about Mark Cho, the co-founder of The Armoury, co-owner of Drake's.
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Zero-shotCelebvDub — Sample #5
<text>
But you still have a chance to make things right because I'm here.
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Zero-shotVoxCeleb2 — Sample #1
<text>
Getting to come back for the six and really finish out strong, I guess I think that we all, I I'm really happy. When I read the finale and stuff, I thought I couldn't imagine a better way to finish things, so.
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Zero-shotVoxCeleb2 — Sample #2
<text>
Yeah, there's uh an engagement with Chloe, so that's kind of a big deal for him and it's probably gonna happen, you know, leading towards the wedding and stuff. There's a lot of uh you know.
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Zero-shotVoxCeleb2 — Sample #3
<text>
Yeah, I had an interviewer ask me once, what would you be if you weren't a musician, and my answer was, unemployed.
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Zero-shotVoxCeleb2 — Sample #4
<text>
Celine Dion and Mariah Carey and Aretha Franklin. I love the big voice divas. That that's who I gravitated to as a little girl. Um and um...
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Zero-shotVoxCeleb2 — Sample #5
<text>
I would imagine there are two major reasons. The first reason is we had phenomenal writers. And the writers told incredible stories about hope, about the future, about mankind. We weren't busy about trying to correct the other world's problems. We were busy about trying to correct our own problems. So, the writing is foremost. The secondary important factor was the norm.
Ground Truth
Reference
AlignDiT
VoiceCraft-Dub
FunCineForge
HoliDubber (Ours)
Text-Prompt GuidedCelebVDub — Sample #1
<speaker_profile>
female, young adult, clear voice, natural accent.
<speech_instruct>
Speaking at a moderate pace with a thoughtful and appreciative tone. The voice is steady and calm, with no signs of distress or urgency.
<audio_caption>
No background music is present. There are no discernible ambient sounds or sound effects. The recording is clear and clean, with only the speaker’s voice audible.
<text>
They're really kind of opposite in their styles and his tone is so so unique.
Ground Truth
FunCineForge
HoliDubber (Ours)
Text-Prompt GuidedCelebVDub — Sample #2
<speaker_profile>
male, adult, clear voice, standard accent.
<speech_instruct>
Normal speaking pace, neutral emotional tone.
<audio_caption>
No background music is present. There is a faint, low-level electronic hum in the background, possibly from recording equipment or ambient room noise. The sound environment is otherwise quiet and acoustically dry.
<text>
If you saw my video about the custom Christian Clins with the salmon dial, you might remember that we spoke about Mark Cho, the co-founder of The Armoury, co-owner of Drake's.
Ground Truth
FunCineForge
HoliDubber (Ours)
Text-Prompt GuidedCelebVDub — Sample #3
<speaker_profile>
female, young adult, clear voice, neutral accent.
<speech_instruct>
Speaking in a calm, deliberate tone with a slightly persuasive quality; no tremor or breathiness detected.
<audio_caption>
No background music is present. There is a faint, low-level electronic hiss, likely from recording equipment. No other ambient or environmental sounds are audible.
<text>
But you still have a chance to make things right because I'm here.
Ground Truth
FunCineForge
HoliDubber (Ours)
Text-Prompt GuidedVoxCeleb2 — Sample #1
<speaker_profile>
male, young adult, clear voice, standard North American accent.
<speech_instruct>
Speaking at a moderate pace with a reflective and positive tone. Slight hesitation between phrases, but overall calm and conversational.
<audio_caption>
No background music is present. The audio contains only the speaker’s voice and a faint, continuous low-frequency hum in the background, likely from electronic equipment. The sound environment is dry, suggesting an indoor recording space with minimal reverberation.
<text>
Getting to come back for the six and really finish out strong, I guess I think that we all, I I'm really happy. When I read the finale and stuff, I thought I couldn't imagine a better way to finish things, so.
Ground Truth
FunCineForge
HoliDubber (Ours)
Text-Prompt GuidedVoxCeleb2 — Sample #2
<speaker_profile>
male, young adult, standard American accent, clear voice.
<speech_instruct>
Speaking at a moderate pace with a neutral, conversational tone.\n
<audio_caption>
No background music is present. There is a faint, consistent hum in the background, possibly from electronic equipment or air conditioning. The overall recording environment sounds quiet and indoor.
<text>
Yeah, there's uh an engagement with Chloe, so that's kind of a big deal for him and it's probably gonna happen, you know, leading towards the wedding and stuff. There's a lot of uh you know.
Ground Truth
FunCineForge
HoliDubber (Ours)
Text-Prompt GuidedVoxCeleb2 — Sample #3
<speaker_profile>
male, young adult, neutral tone.
<speech_instruct>
Normal speaking pace, conversational tone with slight hesitation at the beginning.
<audio_caption>
No background music is present. There are no ambient or environmental sound effects audible. The recording is focused solely on the speaker with minimal room tone.
<text>
Yeah, I had an interviewer ask me once, what would you be if you weren't a musician, and my answer was, unemployed.
Ground Truth
FunCineForge
HoliDubber (Ours)
Text-Prompt GuidedVoxCeleb2 — Sample #4
<speaker_profile>
female, young adult to middle-aged, standard American accent, clear and warm voice.
<speech_instruct>
Speaking at a moderate, conversational pace. Tone is reflective and nostalgic, with natural pauses and filler words (“um”). No vocal distress or unusual qualities.
<audio_caption>
No background music is present. The environment is quiet with only a faint, low-level electronic hiss typical of indoor recording equipment. No ambient sounds or external noises are detectable.\n
<text>
Celine Dion and Mariah Carey and Aretha Franklin. I love the big voice divas. That that's who I gravitated to as a little girl. Um and um...
Ground Truth
FunCineForge
HoliDubber (Ours)
Text-Prompt GuidedVoxCeleb2 — Sample #5
<speaker_profile>
male, middle-aged, standard American accent, calm and measured tone.
<speech_instruct>
Speaking at a moderate pace, with a calm and reflective tone. The voice is clear and steady, with no signs of hesitation, trembling, or emotional intensity.
<audio_caption>
No background music is present. There is a continuous, low-level ambient sound of what appears to be distant city traffic, including faint vehicle engines and possible horns in the far distance. The sound is constant throughout and suggests an outdoor urban environment.\n
<text>
I would imagine there are two major reasons. The first reason is we had phenomenal writers. And the writers told incredible stories about hope, about the future, about mankind. We weren't busy about trying to correct the other world's problems. We were busy about trying to correct our own problems. So, the writing is foremost. The secondary important factor was the norm.
Ground Truth
FunCineForge
HoliDubber (Ours)
HoliDub-BenchComplex Acoustic Scene — Sample #1
<speaker_profile>
male, young adult to middle-aged, clear voice.
<speech_instruct>
Normal speaking pace, conversational tone, sounds reflective and engaged.
<audio_caption>
There is no background music. The environment includes ambient crowd noise, consistent with a public or semi-public indoor setting. No distinct sound effects such as impacts, doors, or weather are present. The main voice is close and clear, with background noise slightly muffled and distant.
<text>
It was earnest. It had goosebumps. It had, you know, fist pump moments. And we knew we could tap into that because we knew how it made us feel.
Ground Truth
HoliDubber (Ours)
HoliDub-BenchComplex Acoustic Scene — Sample #2
<speaker_profile>
male, adult, likely middle-aged, has a noticeable foreign accent, possibly Spanish or Latin American. Voice is clear but slightly breathy at times
<speech_instruct>
Speaking at a moderate pace with a reflective, thoughtful tone. There are pauses and hesitations, suggesting he is formulating his thoughts as he speaks. The voice is calm and expressive.
<audio_caption>
No background music is present. A continuous, low-level murmur of a crowd is audible throughout, suggesting the speaker is in a public indoor space such as a museum or gallery. The ambient sound is diffuse and does not include any distinct environmental effects like footsteps, doors, or movement.
<text>
when I visit those museums and I see the sensibility of this painter, how he describe life, how he goes to our subconscious, how he goes to our dreams world and, you know, propose.
Ground Truth
HoliDubber (Ours)
HoliDub-BenchComplex Acoustic Scene — Sample #3
<speaker_profile>
male, adult, medium-low pitch, British accent.
<speech_instruct>
Speaking with a formal, appreciative tone, at a moderate pace, with a slightly amplified voice as if addressing a crowd. The voice is clear and steady, with no signs of nervousness or hesitation.
<audio_caption>
No background music is present. The environment contains loud, sustained applause and cheering from a large crowd, consistent with a public event or performance. The applause begins immediately after the speech ends and continues for several seconds. The crowd noise is layered and spatially diffuse, suggesting a wide, reverberant venue.
<text>
The crowds are wonderful. And I love the German people and your great country.
Ground Truth
HoliDubber (Ours)
HoliDub-BenchComplex Acoustic Scene — Sample #4
<speaker_profile>
male, adult, American accent, clear voice.
<speech_instruct>
Normal speaking rate, neutral and directive tone.
<audio_caption>
No background music is present. There is a faint, low-level ambient noise consistent with an audience or group setting.
<text>
Show the lady with the cue card. Cut over to her.
Ground Truth
HoliDubber (Ours)
HoliDub-BenchComplex Acoustic Scene — Sample #5
<speaker_profile>
male, young adult, natural English accent, voice timbre is clear and conversational.
<speech_instruct>
Speaking at a moderate pace with a casual and slightly amused tone. There is a brief chuckle at the beginning, and the speech contains repetitions (\"I'm gonna\") and filler phrases (\"and then\"), suggesting spontaneous or informal storytelling.
<audio_caption>
The audio opens with audience laughter, indicating a live performance or recording with a crowd. Following the laughter, there is no background music or ambient noise aside from a faint room tone. The speaker's voice is close-miked and prominent, with no detectable reverberation or echo from a large space.
<text>
And so I thought I'm gonna I'm gonna I was bored one day and then I saw my granddad's...
Ground Truth
HoliDubber (Ours)
HoliDub-BenchComplex Acoustic Scene — Sample #6
<speaker_profile>
male, young adult, clear voice.
<speech_instruct>
Normal speaking pace, conversational tone, sounding relaxed and slightly enthusiastic.
<audio_caption>
There is background music present: a continuous, mellow instrumental track with a simple piano melody and soft electronic percussion. The music remains at a low volume throughout, supporting the speech without overpowering it. There are no other ambient or sound effects.
<text>
younger and uh but it's also exciting and cool and I wanted to write about two kids who were sort of living that kind of life.
Ground Truth
HoliDubber (Ours)
HoliDub-BenchComplex Acoustic Scene — Sample #7
<speaker_profile>
female, young adult, American accent, clear voice with melodic intonation.
<speech_instruct>
Spoken at a moderate, conversational pace with an expressive and reflective tone. Voice is confident and clear, with slight upward inflections at the end of phrases.
<audio_caption>
A soft, mellow jazz-style piano melody plays in the background throughout. The music is understated, with a smooth and relaxed rhythm, supporting the speech without overpowering it.
<text>
like when you know the poster girl of rent they I don't look like that I don't look like you know me in the movie I I mean it's a blessing because that means I can kind of morph into whoever people need me to be which is great.
<speech_instruct>
Speaking in a steady, declarative tone with moderate pace and no noticeable emotional inflection.
<audio_caption>
Background music is present: a smooth, low-tempo jazz track featuring a piano and upright bass. The music maintains a consistent, relaxed rhythm throughout, creating a calm and reflective atmosphere. No other ambient or sudden sound effects are heard.
<text>
knows his personality and accepts it as who he is. It's not something he turns on just to be mean. That's just who the guy is.
Ground Truth
HoliDubber (Ours)
HoliDub-BenchComplex Acoustic Scene — Sample #9
<speaker_profile>
female, young adult, standard British accent, clear and articulate voice.
<speech_instruct>
Speaking at a moderate, steady pace with a friendly and informative tone. There are no signs of distress or emotional fluctuation; voice is confident and clear.
<audio_caption>
Background music is present: an upbeat, instrumental electronic track with a steady rhythm and synth-based melody, creating a modern and energetic atmosphere. No other ambient or physical sound effects are audible.
<text>
The Pippa Mann and I have the little blue check mark to say it's really me. I'm also on Twitter, I'm at Pippa Mann there. And same thing, I have the little blue check mark. Now Instagram, Instagram is slacking. I do not have a blue check mark on Instagram but I am still the little at Pippa Mann. So hopefully you can find me on all of those and my name is spelt P-I-P-P-A-M-A-N.